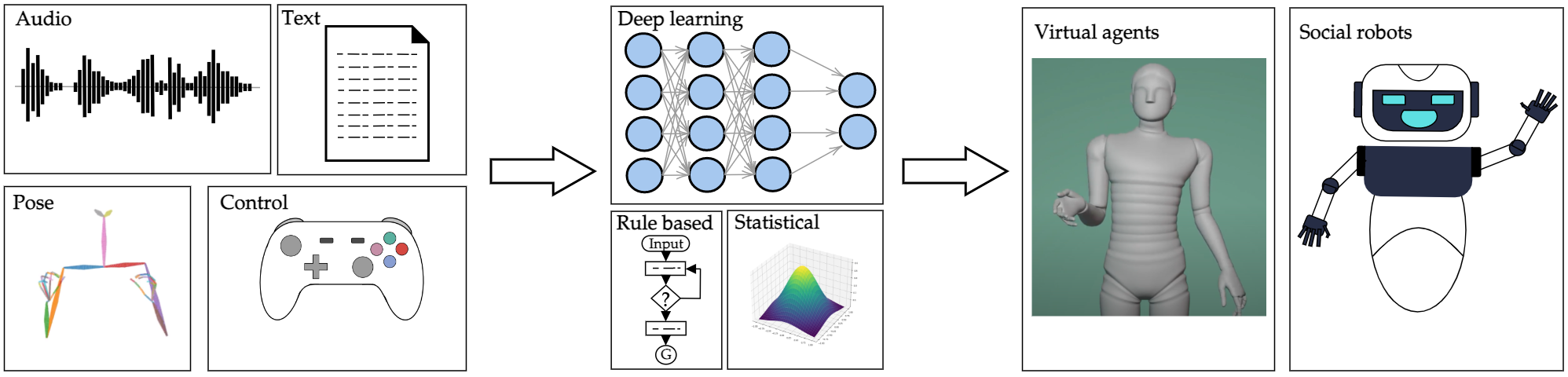
I am an AI Research Scientist at Meta AI working on Human-Centric Multimodal Machine Learning and Generative Modeling. Prior to that I completed my PhD at the Language Technologies Institute at Carnegie Mellon University where I was advised by Dr. Louis-Philippe Morency (LP) in the Multicomp Lab. My research focused on endowing agents and remote avatars with Social Intelligence by means of Multimodal Learning. One of the use-cases where we extensively apply these technologies is Computer Animation. These directions have the potential of making a meaningful impact on remote communication, collaborations, education and mental health for human-human and human-robot interaction, especially now when a lot of social and work spaces are gradually moving online.
In the past, I have also interned at Facebook Reality Labs on generation of nonverbal behaviours for a communicating avatar. As an undergraduate researcher at Indian Institute of Technology(IIT), Kanpur, I worked with Dr. Rajesh Hegde on Spatial Audio and Speaker Diarization, and Dr. Vinay Namboodiri on Video Summarization
News
Feb 2026
Paper A Simple and Effective Reinforcement Learning Method for Text-to-Image Diffusion Fine-tuning accepted at TMLR 2026.
Feb 2026
Preprint Xray-Visual Models: Scaling Vision models on Industry Scale Data now available on arXiv.
Feb 2026
Paper Think Then Embed: Generative Context Improves Multimodal Embedding accepted at ICLR 2026.
February 2025
Paper Multi-Modal Large Language Models as Effective Vision Learners accepted at WACV 2025.
Feb 2023
Survey paper on Co-Speech Gestures accepted in the STAR track at Eurographics 2023.
May 2022
Excited to join Meta AI as an AI Research Scientist
April 2022
Defended my PhD dissertation on Communication Beyond Words: Grounding Visual Body Motion with Language
April 2022
Humbled to be a Highlighted Reviewer at ICLR 2022
March 2022
Paper on Low-Resource Adaptation of Spatio-Temporal Crossmodal Generative Models accepted at CVPR 2022
May 2020
We are organizing the First Workshop on Crossmodal Social Animation at ICCV2021. Consider submissing your work.
December 2020
Succesfully proposed my thesis titled Communication Beyond Words: Grounding Visual Body Motion with Language
September 2020
Paper on Co-Speech Gesture Generation from Language accepted at Findings at EMNLP 2020
September 2020
Paper on Impact of Personality on Non-verbal behvaiours accepted at IVA 2020
August 2020
PATS (Pose-Audio-Transcripts-Style) Dataset released.
August 2020
Code for Style Transfer for Co-Speech Gesture Animation released.
July 2020
Paper on Style Transfer for Co-Speech Gesture Animation accepted at ECCV 2020
August 2019
Paper on Visual Pose Forecasting for Personalized Avatar during Dyadic Conversations accepted at ICMI 2019.
August 2019
Honourable mention in LTI SRS symposium on my talk on Natural Language Grounded Pose Forecasting
July 2019
Paper on Natural Language Grounded Pose Forecasting accepted at 3DV 2019
March 2018
Excited to work at Facebook Reality Labs in Summer'18
January 2018
Paper on Lattice Recurrent Units accepted at AAAI 2018
October 2017
Our survey on Multimodal Machine Learning is online
Book Chapters
1. Challenges and applications in multimodal machine learning
T. Baltrusaitis, C. Ahuja, and L. Morency
The Handbook of Multimodal-Multisensor Interfaces 2018
Pre-prints
1. Xray-Visual Models: Scaling Vision models on Industry Scale Data
S. Mishra, T. Lin, L. Wang, H. Xu, Y. Liu, M. Hsu, C. Ahuja, H. Yuan, J. Cheng, H. Chen, and e. al.
Preprint 2026
We present Xray-Visual, a unified vision model architecture for large-scale image and video understanding trained on industry-scale social media data. Our model leverages over 15 billion curated image-text pairs and 10 billion video-hashtag pairs from Facebook and Instagram, employing robust data curation pipelines that incorporate balancing and noise suppression strategies to maximize semantic diversity while minimizing label noise. We introduce a three-stage training pipeline that combines self-supervised MAE, semi-supervised hashtag classification, and CLIP-style contrastive learning to jointly optimize image and video modalities. Our architecture builds on a Vision Transformer backbone enhanced with efficient token reorganization (EViT) for improved computational efficiency. Extensive experiments demonstrate that Xray-Visual achieves state-of-the-art performance across diverse benchmarks, including ImageNet for image classification, Kinetics and HMDB51 for video understanding, and MSCOCO for cross-modal retrieval. The model exhibits strong robustness to domain shift and adversarial perturbations. We further demonstrate that integrating large language models as text encoders (LLM2CLIP) significantly enhances retrieval performance and generalization capabilities, particularly in real-world environments. Xray-Visual establishes new benchmarks for scalable, multimodal vision models, while maintaining superior accuracy and computational efficiency.
17. A Simple and Effective Reinforcement Learning Method for Text-to-Image Diffusion Fine-tuning
S. Gupta, C. Ahuja, T. Lin, S. Roy, H. Oosterhuis, M. de Rijke, and S. Shukla
TMLR 2026
Reinforcement learning (RL) based fine-tuning has emerged as a powerful approach for aligning diffusion models with black-box objectives. Proximal policy optimization (PPO) is the most popular choice of method for policy optimization. While effective in terms of performance, PPO is highly sensitive to hyper-parameters and involves substantial computational overhead. REINFORCE, on the other hand, mitigates some computational complexities such as high memory overhead and sensitive hyper-parameter tuning, but has suboptimal performance due to high variance and sample inefficiency. While the variance of the REINFORCE can be reduced by sampling multiple actions per input prompt and using a baseline correction term, it still suffers from sample inefficiency. To address these challenges, we systematically analyze the efficiency effectiveness trade-off between REINFORCE and PPO, and propose leave-one-out PPO (LOOP), a novel RL for diffusion fine-tuning method. LOOP combines variance reduction techniques from REINFORCE, such as sampling multiple actions per input prompt and a baseline correction term, with the robustness and sample efficiency of PPO via clipping and importance sampling. Our results demonstrate that LOOP effectively improves diffusion models on various black-box objectives, and achieves a better balance between computational efficiency and performance.
16. Think Then Embed: Generative Context Improves Multimodal Embedding
X. Cui, J. Cheng, H. Chen, S. Shukla, A. Awasthi, X. Pan, C. Ahuja, S. Mishra, T. Tian, Q. Guo, S. Lim, A. Singh, and X. Fan
ICLR 2026
There is a growing interest in Universal Multimodal Embeddings (UME), where models are required to generate task-specific representations. While recent studies show that Multimodal Large Language Models (MLLMs) perform well on such tasks, they treat MLLMs solely as encoders, overlooking their generative capacity. However, such an encoding paradigm becomes less effective as instructions become more complex and require compositional reasoning. Inspired by the proven effectiveness of chain-of-thought reasoning, we propose a general Think-Then-Embed (TTE) framework for UME, composed of a reasoner and an embedder. The reasoner MLLM first generates reasoning traces that explain complex queries, followed by an embedder that produces representations conditioned on both the original query and the intermediate reasoning. This explicit reasoning step enables more nuanced understanding of complex multimodal instructions. Our contributions are threefold. First, by leveraging a powerful MLLM reasoner, we achieve state-of-the-art performance on the MMEB-V2 benchmark, surpassing proprietary models trained on massive in-house datasets. Second, to reduce the dependency on large MLLM reasoners, we finetune a smaller MLLM reasoner using high-quality embedding-centric reasoning traces, achieving the best performance among open-source models with a 7% absolute gain over recently proposed models. Third, we investigate strategies for integrating the reasoner and embedder into a unified model for improved efficiency without sacrificing performance.
15. Multi-Modal Large Language Models are Effective Vision Learners
L. Sun, C. Ahuja, P. Chen, M. D\’Zmura, K. Batmanghelich, and P. Bontrager
WACV 2025
Large language models (LLMs), pre-trained on vast amounts of text, have shown remarkable abilities in understanding general knowledge and commonsense. Therefore, it’s desirable to leverage pre-trained LLM to help solve computer vision tasks. Previous works on multi-modal LLM mainly focus on the generation capability. In this work, we propose LLM-augmented visual representation learning (LMVR). Our approach involves initially using a vision encoder to extract features, which are then projected into the word embedding space of the LLM. The LLM then generates responses based on the visual representation and a text prompt. Finally, we aggregate sequence-level features from the hidden layers of the LLM to obtain image-level representations. We conduct extensive experiments on multiple datasets, and have the following findings: (a) LMVR outperforms traditional vision encoder on various downstream tasks, and effectively learns the correspondence between words and image regions; (b) LMVR improves the generalizability compared to using a vision encoder alone, as evidenced by its superior resistance to domain shift; (c) LMVR improves the robustness of models to corrupted and perturbed visual data. Our findings demonstrate LLM-augmented visual representation learning is effective as it learns object-level concepts and commonsense knowledge.
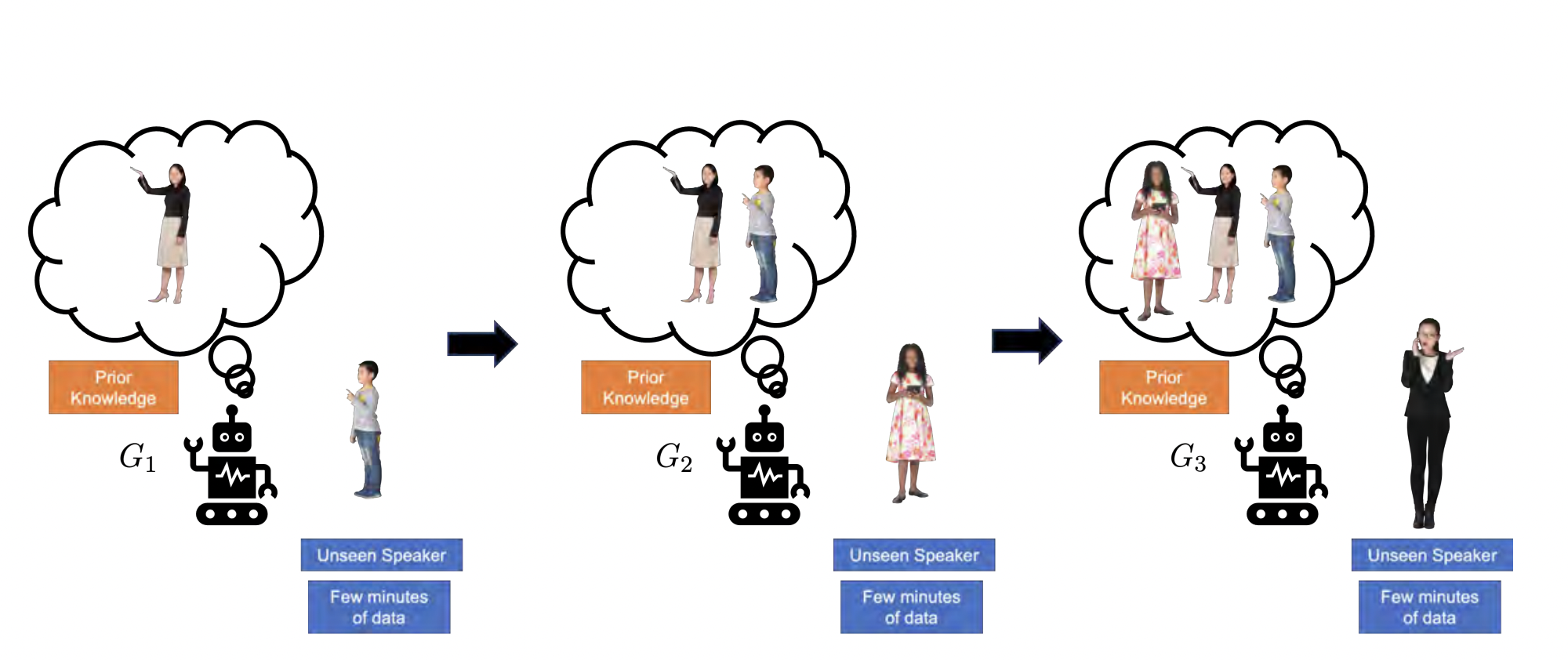
14. Continual Learning for Personalized Co-speech Gesture Generation C. Ahuja, P. Joshi, R. Ishii, and L. Morency
ICCV 2023
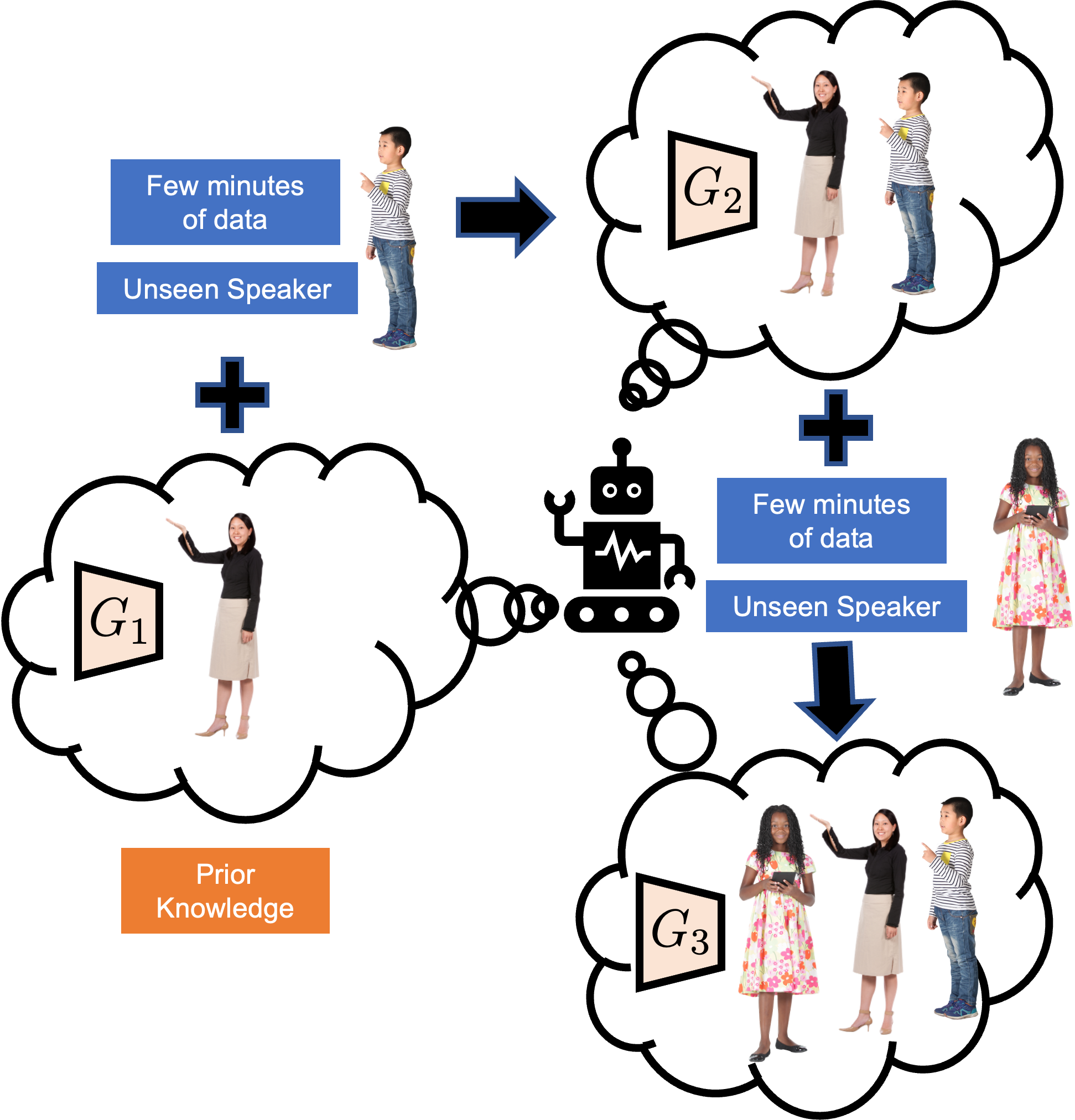
Co-speech gestures are a key channel of human communication, making them important for personalized chat agents to generate. In the past, gesture generation models assumed that data for each speaker is available all at once, and in large amounts. However in practical scenarios, speaker data comes sequentially and in small amounts as the agent personalizes with more speakers, akin to a continual learning paradigm. While more recent works have shown progress in adapting to low-resource data, they catastrophically forget the gesture styles of initial speakers they were trained on. Also, prior generative continual learning works are not multimodal, making this space less studied. In this paper, we explore this new paradigm and propose C-DiffGAN: an approach that continually learns new speaker gesture styles with only a few minutes of per-speaker data, while retaining previously learnt styles. Inspired by prior continual learning works, C-DiffGAN encourages knowledge retention by 1) generating reminiscences of previous low-resource speaker data, then 2) crossmodally aligning to them to mitigate catastrophic forgetting. We quantitatively demonstrate improved performance and reduced forgetting over strong baselines through standard continual learning measures, reinforced by a qualitative user study that shows that our method produces more natural, style-preserving gestures.
13. Lecture Presentations Multimodal Dataset: Towards Understanding Multimodality in Educational Videos
D. Lee, C. Ahuja, P. Liang, S. Natu, and L. Morency
ICCV 2023
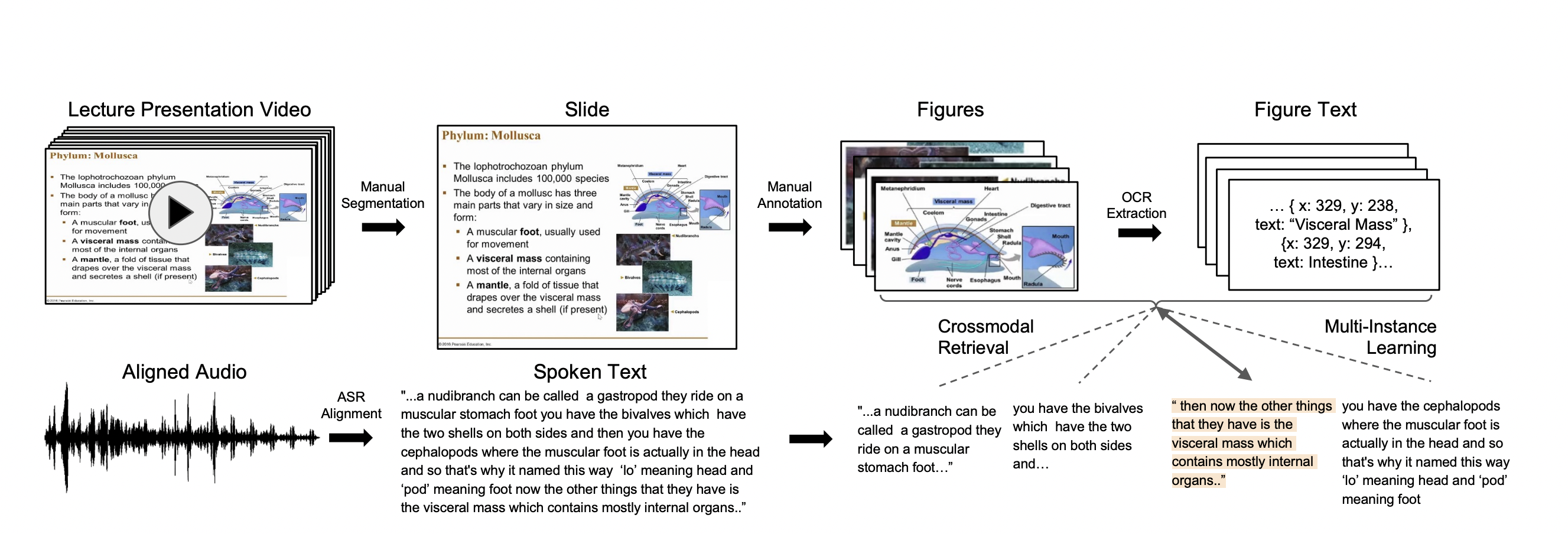
Many educational videos use slide presentations, a sequence of visual pages that contain text and figures accompanied by spoken language, which are constructed and presented carefully in order to optimally transfer knowledge to students. Previous studies in multimedia and psychology attribute the effectiveness of lecture presentations to their multimodal nature. As a step toward developing vision-language models to aid in student learning as intelligent teacher assistants, we introduce the Lecture Presentations Multimodal (LPM) Dataset as a large-scale benchmark testing the capabilities of vision-and-language models in multimodal understanding of educational videos. Our dataset contains aligned slides and spoken language, for 180+ hours of video and 9000+ slides, with 10 lecturers from various subjects (e.g., computer science, dentistry, biology). We introduce three research tasks, (1) figure-totext retrieval, (2) text-to-figure retrieval, and (3) generation of slide explanations, which are grounded in multimedia learning and psychology principles to test a vision-language model’s understanding of multimodal content. We provide manual annotations to help implement these tasks and establish baselines on them. Comparing baselines and human student performances, we find that state-of-the-art vision-language models (zero-shot and fine-tuned) struggle in (1) weak crossmodal alignment between slides and spoken text, (2) learning novel visual mediums, (3) technical language, and (4) long-range sequences. We introduce PolyViLT, a novel multimodal transformer trained with a multi-instance learning loss that is more effective than current approaches for retrieval. We conclude by shedding light on the challenges and opportunities in multimodal understanding of educational presentation videos.
12. A Comprehensive Review of Data-Driven Co-Speech Gesture Generation
S. Nyatsanga, T. Kucherenko, C. Ahuja, G. Henter, and M. Neff
EUROGRAPHICS 2023
Gestures that accompany speech are an essential part of natural and efficient embodied human communication. The automatic generation of such co-speech gestures is a long-standing problem in computer animation and is considered an enabling technology in film, games, virtual social spaces, and for interaction with social robots. The problem is made challenging by the idiosyncratic and non-periodic nature of human co-speech gesture motion, and by the great diversity of communicative functions that gestures encompass. Gesture generation has seen surging interest recently, owing to the emergence of more and larger datasets of human gesture motion, combined with strides in deep-learning-based generative models, that benefit from the growing availability of data. This review article summarizes co-speech gesture generation research, with a particular focus on deep generative models. First, we articulate the theory describing human gesticulation and how it complements speech. Next, we briefly discuss rule-based and classical statistical gesture synthesis, before delving into deep learning approaches. We employ the choice of input modalities as an organizing principle, examining systems that generate gestures from audio, text, and non-linguistic input. We also chronicle the evolution of the related training data sets in terms of size, diversity, motion quality, and collection method. Finally, we identify key research challenges in gesture generation, including data availability and quality; producing human-like motion; grounding the gesture in the co-occurring speech in interaction with other speakers, and in the environment; performing gesture evaluation; and integration of gesture synthesis into applications. We highlight recent approaches to tackling the various key challenges, as well as the limitations of these approaches, and point toward areas of future development.
11. Communication Beyond Words: Grounding Visual Body Motion with Language C. Ahuja
PhD dissertation, Carnegie Mellon University 2022
The central theme of this thesis is to understand the two-way relationship (a.k.a. grounding) between human body motions and its associated spoken language, which includes both verbal and vocal cues. Understanding this complex relationship will help us to both better understand the meaning intended by body gestures and provide us with the knowledge necessary to generate more realistic nonverbal body animations with interactive technologies. With these motivations in mind, we propose three key challenges: (1) Nonverbal Grounding as the core component of this thesis to study the close relationship between spoken language and motion, (2) Personalization to better understand idiosyncrasies and commonalities on how people gesture, and (3) Low Resource Learning when gestures occur infrequently or the amount of labeled data is limited and often unbalanced. These challenges investigate the commonalities, uniqueness and generalizability of visual body communication respectively in the presence of verbal and vocal information
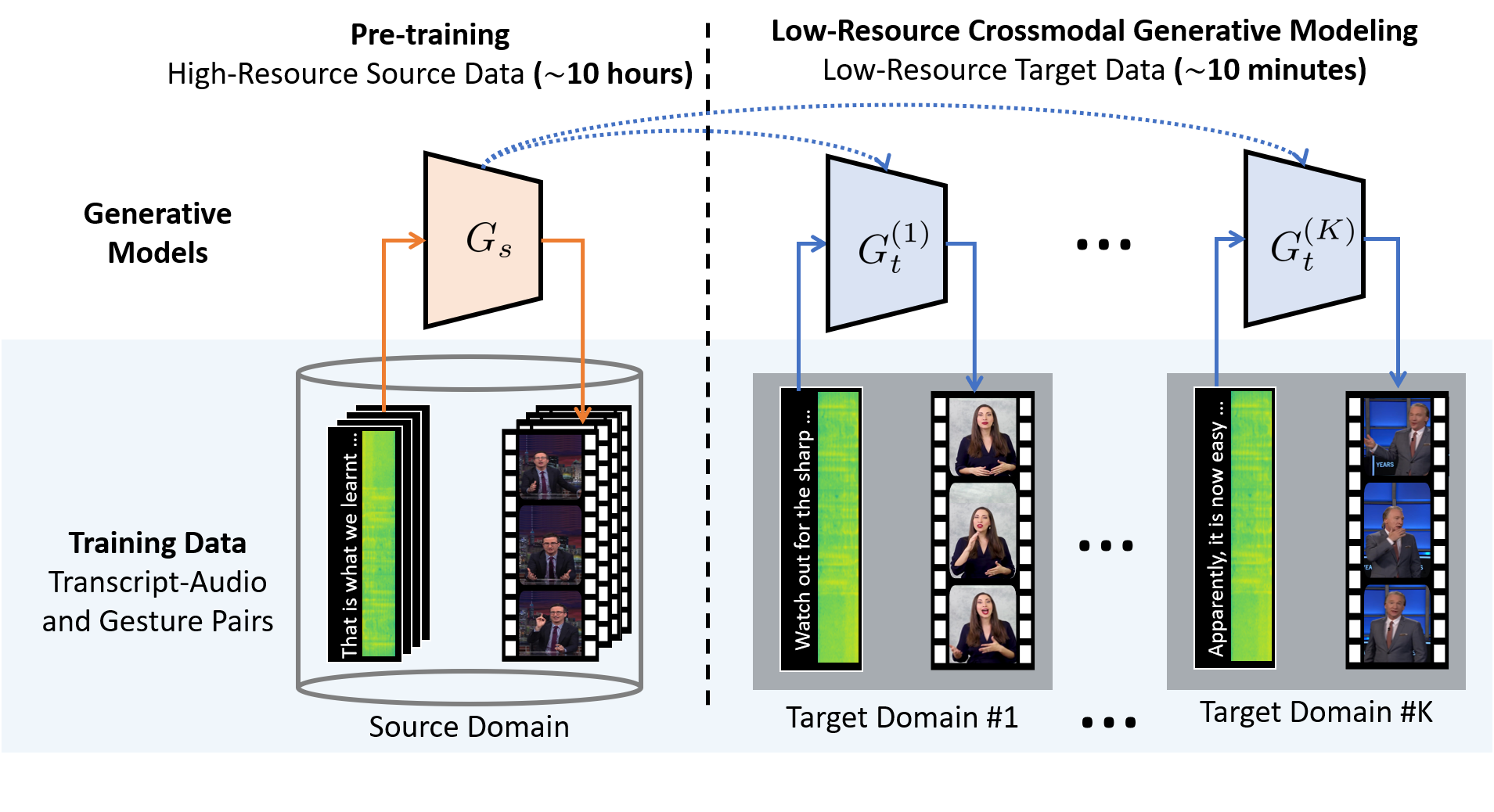
10. Low-Resource Adaptation of Spatio-Temporal Crossmodal Generative Models C. Ahuja, D. Lee, and L. Morency
CVPR 2022
Personalizing an avatar for co-speech gesture generation from spoken language requires learning the idiosyncrasies of a person’s gesture style from a small amount of data. Previous methods in gesture generation require large amounts of data for each speaker, which is often infeasible. We propose an approach, named DiffGAN, that efficiently personalizes co-speech gesture generation models of a high-resource source speaker to target speaker with just 2 minutes of target training data. A unique characteristic of DiffGAN is its ability to account for the crossmodal grounding shift, while also addressing the distribution shift in the output domain. We substantiate the effectiveness of our approach a large scale publicly available dataset through quantitative, qualitative and user studies, which show that our proposed methodology significantly outperforms prior approaches for low-resource adaptation of gesture generation. Code and videos can be found at https://chahuja.com/diffgan.
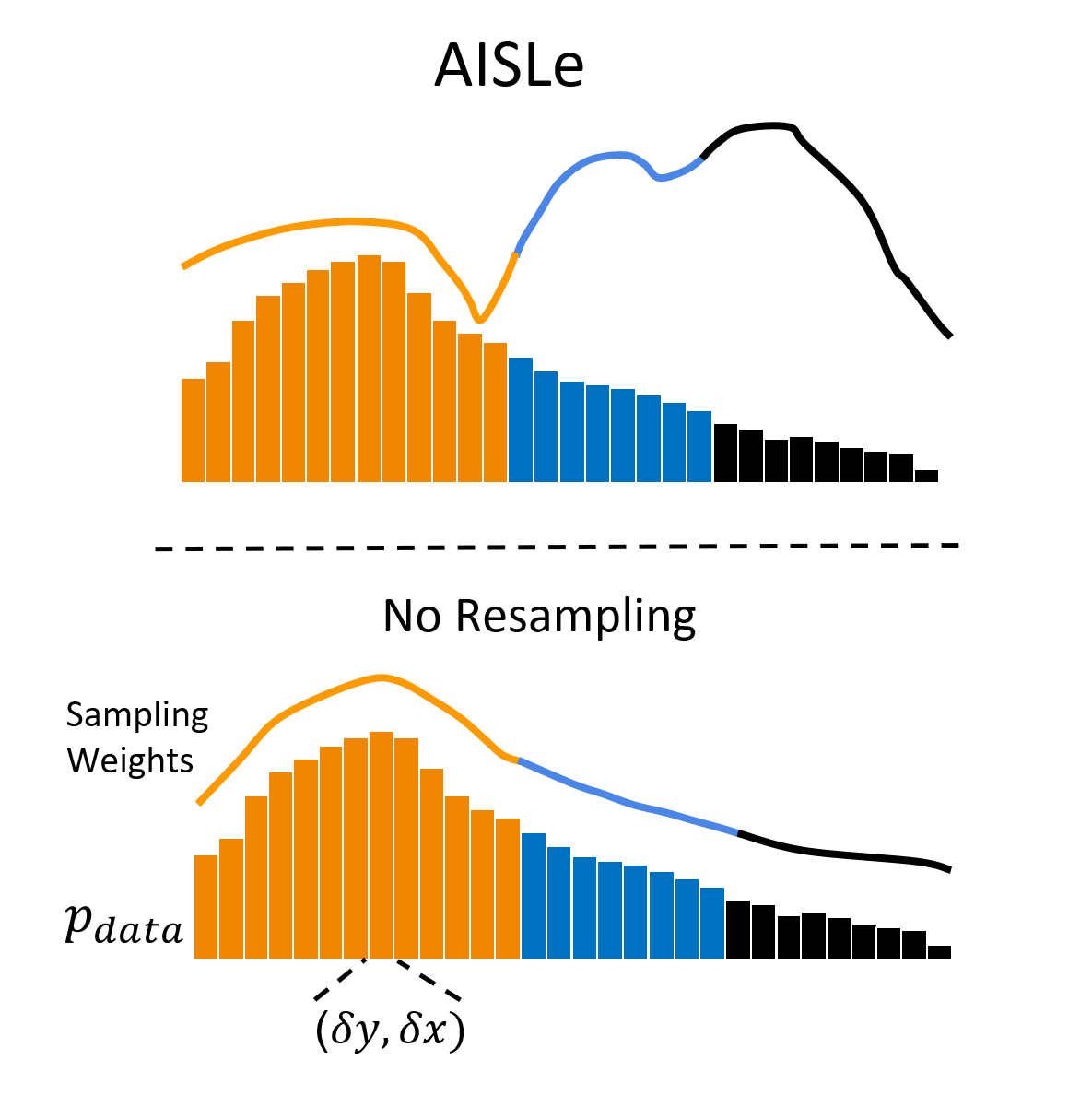
9. No Gestures Left Behind: Learning Relationships between Spoken Language and Freeform Gestures C. Ahuja, D. Lee, R. Ishii, and L. Morency
EMNLP Findings 2020
We study relationships between spoken language and co-speech gestures in context of two key challenges. First, distributions of text and gestures are inherently skewed making it important to model the long tail. Second, gesture predictions are made at a subword level, making it important to learn relationships between language and audio. We introduce Adversarial Importance Sampled Learning, which combines adversarial learning with importance sampling to strike a balance between precision and coverage. We substantiate the effectiveness of our approach through large-scale quantitative and user studies, which show that our proposed methodology significantly outperforms previous stateof-the-art approaches for gesture generation.
8. Impact of Personality on Nonverbal Behavior Generation
R. Ishii, C. Ahuja, Y. Nakano, and L. Morency
IVA 2020
To realize natural-looking virtual agents, one key technical challenge is to automatically generate nonverbal behaviors from spoken language. Since nonverbal behavior varies depending on personality, it is important to generate these nonverbal behaviors to match the expected personality of a virtual agent. In this work, we study how personality traits relate to the process of generating individual nonverbal behaviors from the whole body, including the head, eye gaze, arms, and posture. To study this, we first created a dialogue corpus including transcripts, a broad range of labelled nonverbal behaviors, and the Big Five personality scores of participants in dyad interactions. We constructed models that can predict each nonverbal behavior label given as an input language representation from the participants’ spoken sentences. Our experimental results show that personality can help improve the prediction of nonverbal behaviors.
7. Style Transfer for Co-Speech Gesture Animation: A Multi-Speaker Conditional Mixture Approach C. Ahuja, D. Lee, Y. Nakano, and L. Morency
ECCV 2020
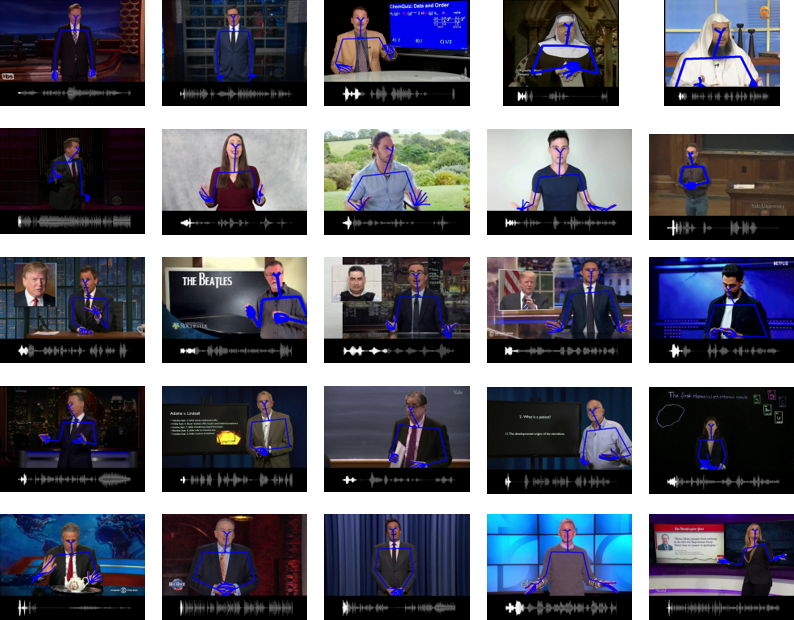
How can we teach robots or virtual assistants to gesture naturally? Can we go further and adapt the gesturing style to follow a specific speaker? Gestures that are naturally timed with corresponding speech during human communication are called co-speech gestures. A key challenge, called gesture style transfer, is to learn a model that generates these gestures for a speaking agent ‘A’ in the gesturing style of a target speaker ‘B’. A secondary goal is to simultaneously learn to generate co-speech gestures for multiple speakers while remembering what is unique about each speaker. We call this challenge style preservation. In this paper, we propose a new model, named Mix-StAGE, which trains a single model for multiple speakers while learning unique style embeddings for each speaker’s gestures in an end-to-end manner. A novelty of Mix-StAGE is to learn a mixture of generative models which allows for conditioning on the unique gesture style of each speaker. As Mix-StAGE disentangles style and content of gestures, gesturing styles for the same input speech can be altered by simply switching the style embeddings. Mix-StAGE also allows for style preservation when learning simultaneously from multiple speakers. We also introduce a new dataset, Pose-Audio-Transcript-Style (PATS), designed to study gesture generation and style transfer. Our proposed Mix-StAGE model significantly outperforms the previous state-of-the-art approach for gesture generation and provides a path towards performing gesture style transfer across multiple speakers. Link to code, data, and videos: http://chahuja.com/mix-stage
6. To React or not to React: End-to-End Visual Pose Forecasting for Personalized Avatar during Dyadic Conversations C. Ahuja, S. Ma, L. Morency, and Y. Sheikh
ICMI 2019
Non verbal behaviours such as gestures, facial expressions, body posture, and para-linguistic cues have been shown to complement or clarify verbal messages. Hence to improve telepresence, in form of an avatar, it is important to model these behaviours, especially in dyadic interactions. Creating such personalized avatars not only requires to model intrapersonal dynamics between a avatar’s speech and their body pose, but it also needs to model interpersonal dynamics with the interlocutor present in the conversation. In this paper, we introduce a neural architecture named Dyadic Residual-Attention Model (DRAM), which integrates intrapersonal (monadic) and interpersonal (dyadic) dynamics using selective attention to generate sequences of body pose conditioned on audio and body pose of the interlocutor and audio of the human operating the avatar. We evaluate our proposed model on dyadic conversational data consisting of pose and audio of both participants, confirming the importance of adaptive attention between monadic and dyadic dynamics when predicting avatar pose. We also conduct a user study to analyze judgments of human observers. Our results confirm that the generated body pose is more natural, models intrapersonal dynamics and interpersonal dynamics better than non-adaptive monadic/dyadic models.
5. Language2Pose: Natural Language Grounded Pose Forecasting C. Ahuja and L. Morency
3DV 2019
Generating animations from natural language sentences finds its applications in a a number of domains such as movie script visualization, virtual human animation and, robot motion planning. These sentences can describe different kinds of actions, speeds and direction of these actions, and possibly a target destination. The core modeling challenge in this language-to-pose application is how to map linguistic concepts to motion animations. In this paper, we address this multimodal problem by introducing a neural architecture called Joint Language-toPose (or JL2P), which learns a joint embedding of language and pose. This joint embedding space is learned end-toend using a curriculum learning approach which emphasizes shorter and easier sequences first before moving to longer and harder ones. We evaluate our proposed model on a publicly available corpus of 3D pose data and humanannotated sentences. Both objective metrics and human judgment evaluation confirm that our proposed approach is able to generate more accurate animations and are deemed visually more representative by humans than other data driven approaches.
4. Lattice Recurrent Unit: Improving Convergence and Statistical Efficiency for Sequence Modeling C. Ahuja and L. Morency
AAAI 2018
Recurrent neural networks have shown remarkable success in modeling sequences. However low resource situations still adversely affect the generalizability of these models. We introduce a new family of models, called Lattice Recurrent Units (LRU), to address the challenge of learning deep multi-layer recurrent models with limited resources. LRU models achieve this goal by creating distinct (but coupled) flow of information inside the units: a first flow along time dimension and a second flow along depth dimension. It also offers a symmetry in how information can flow horizontally and vertically. We analyze the effects of decoupling three different components of our LRU model: Reset Gate, Update Gate and Projected State. We evaluate this family of new LRU models on computational convergence rates and statistical efficiency. Our experiments are performed on four publicly-available datasets, comparing with Grid-LSTM and Recurrent Highway networks. Our results show that LRU has better empirical computational convergence rates and statistical efficiency values, along with learning more accurate language models.
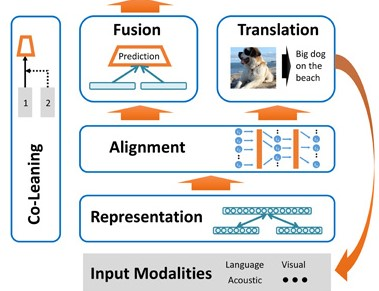
3. Multimodal Machine Learning: A Survey and Taxonomy
T. Baltrusaitis, C. Ahuja, and L. Morency
TPAMI 2017
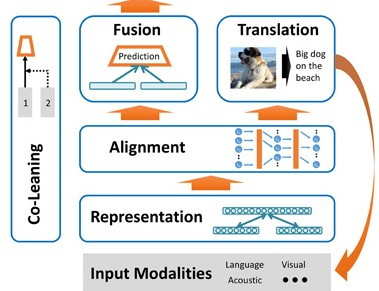
—Our experience of the world is multimodal - we see objects, hear sounds, feel texture, smell odors, and taste flavors. Modality refers to the way in which something happens or is experienced and a research problem is characterized as multimodal when it includes multiple such modalities. In order for Artificial Intelligence to make progress in understanding the world around us, it needs to be able to interpret such multimodal signals together. Multimodal machine learning aims to build models that can process and relate information from multiple modalities. It is a vibrant multi-disciplinary field of increasing importance and with extraordinary potential. Instead of focusing on specific multimodal applications, this paper surveys the recent advances in multimodal machine learning itself and presents them in a common taxonomy. We go beyond the typical early and late fusion categorization and identify broader challenges that are faced by multimodal machine learning, namely: representation, translation, alignment, fusion, and co-learning. This new taxonomy will enable researchers to better understand the state of the field and identify directions for future research.
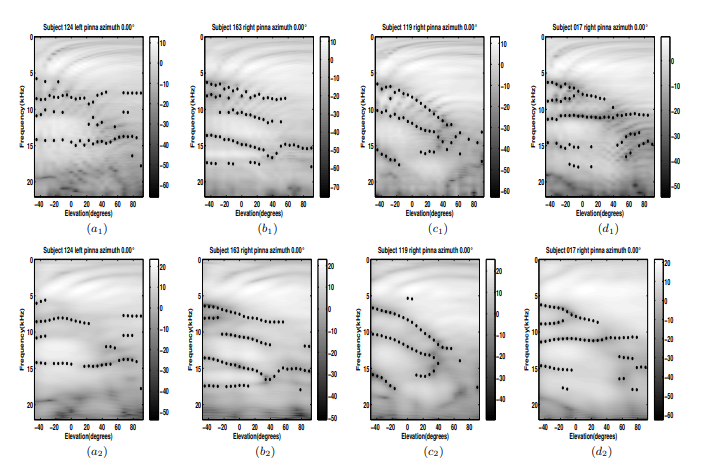
2. Fast modelling of pinna spectral notches from HRTFs using linear prediction residual cepstrum C. Ahuja and R. Hegde
ICASSP 2014
Developing individualized head related transfer functions (HRTF) is an essential requirement for accurate virtualization of sound. However it is time consuming and complicated for both the subject and the developer. Obtaining the spectral notches which are the most prominent features of HRTF is very important to reconstruct the head related impulse response (HRIR) accurately. In this paper, a method suitable for fast computation of the frequencies of spectral notches is proposed. The linear prediction residual cepstrum is used to compute the spectral notches with a high degree of accuracy in this work. Subsequent use of Batteaus Reflection model to overlay the spectral notches on the pinna images indicate that the proposed method is able to provide finer contours. Experiments on reconstruction of the HRIR indicates that the method performs better than other methods.
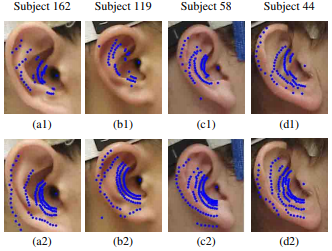
1. Extraction of pinna spectral notches in the median plane of a virtual spherical microphone array
A. Sohni, C. Ahuja, and R. Hegde
HSCMA 2014
In this paper, a fast method for the extraction of pinna spectral notches (PSN) in the median plane of a virtual spherical microphone array is discussed. In general, PSN can be extracted from the Head Related Impulse Response (HRIR) measured by a spherical array of microphones. However, the PSN extracted herein are computationally complex and also not accurate at lower elevation angles. This work proposes a novel approach to reconstruct the HRIR using microphones over the median plane of a virtual spherical array. The virtual spherical array itself is simulated using the Fourier Bessel series (FBS). Subsequently, these HRIRs are used to extract the PSN. This method is computationally efficient since it is done over the median plane rather than over the complete sphere. On the other hand, it is also accurate due to the utilization of the Fourier Bessel series in the extraction of the PSN. Experimental results obtained on the CIPIC database indicate a high degree of resemblance to the actual pinna walls, even at the lower elevation angles. The results are motivating enough for the method to be considered for resolving elevation ambiguity in 3D audio.
Resources
1. PATS Dataset: Pose, Audio, Transcripts and Style C. Ahuja, D. Lee, Y. Nakano, and L. Morency
Education
Ph.D. in Language Technologies
(4.02/4.00)
Carnegie Mellon University | Pittsburgh, PA
End-to-End Visual Pose Forecasting for Personalized Avatar during Dyadic Conversations ACM International Conference on Multimodal Interaction, Suzhou, China
October 2019
Natural Language Grounded Pose Forecasting LTI Student Research Symposium, Pittsburgh PA
August 2019
Student Mentorship
Dong Won Lee (CMU BS → CMU MS in Machine Learning): Self-supervised generative models.
Shradha Sehgal (IIIT Hyderabad B.Tech.): Evaluation of generative models.
Arvin Wu (CMU BS): Social intelligence benchmarking.
Nikitha Murikinati (CMU BS): Study of relationships between co-speech gestures and prosody.
Sharath Rao (CMU MS → PlayStation) Back-channel prediction in dyadic conversations.
Qingtao Hu (CMU MS → Amazon): Unsupervised disentanglement of style and content in images.
Anirudha Rayasam (CMU MS → Google): Language grounded pose forecasting.