Abstract
How can we teach robots or virtual assistants to gesture naturally? Can we go further and adapt the gesturing style to follow a specific speaker? Gestures that are naturally timed with corresponding speech during human communication are called co-speech gestures. A key challenge, called gesture style transfer, is to learn a model that generates these gestures for a speaking agent 'A' in the gesturing style of a target speaker 'B'. A secondary goal is to simultaneously learn to generate co-speech gestures for multiple speakers while remembering what is unique about each speaker. We call this challenge style preservation. In this paper, we propose a new model, named Mix-StAGE, which trains a single model for multiple speakers while learning unique style embeddings for each speaker's gestures in an end-to-end manner. A novelty of Mix-StAGE is to learn a mixture of generative models which allows for conditioning on the unique gesture style of each speaker. As Mix-StAGE disentangles style and content of gestures, gesturing styles for the same input speech can be altered by simply switching the style embeddings. Mix-StAGE also allows for style preservation when learning simultaneously from multiple speakers. We also introduce a new dataset, Pose-Audio-Transcript-Style (PATS), designed to study gesture generation and style transfer. Our proposed Mix-StAGE model significantly outperforms the previous state-of-the-art approach for gesture generation and provides a path towards performing gesture style transfer across multiple speakers.Videos
Teaser
Demo
Navigating this demo: The top left represents the style space of all the speakers in our pretrained model. On the top right you will view can view the videos for both Style Transfer and Style Preservation. Both the animations are generated by our model. The grid bottom can take you through all the styles in the model. For example, if you choose 'lec_cosmic' as the style and the '0'th audio in the 'maher' column, the generated animation will be in the style of 'lec_cosmic' but with the audio of 'maher'. You can choose from any style and any audio listed in the grid. There are 7 different audios and 8 different styles to choose from.
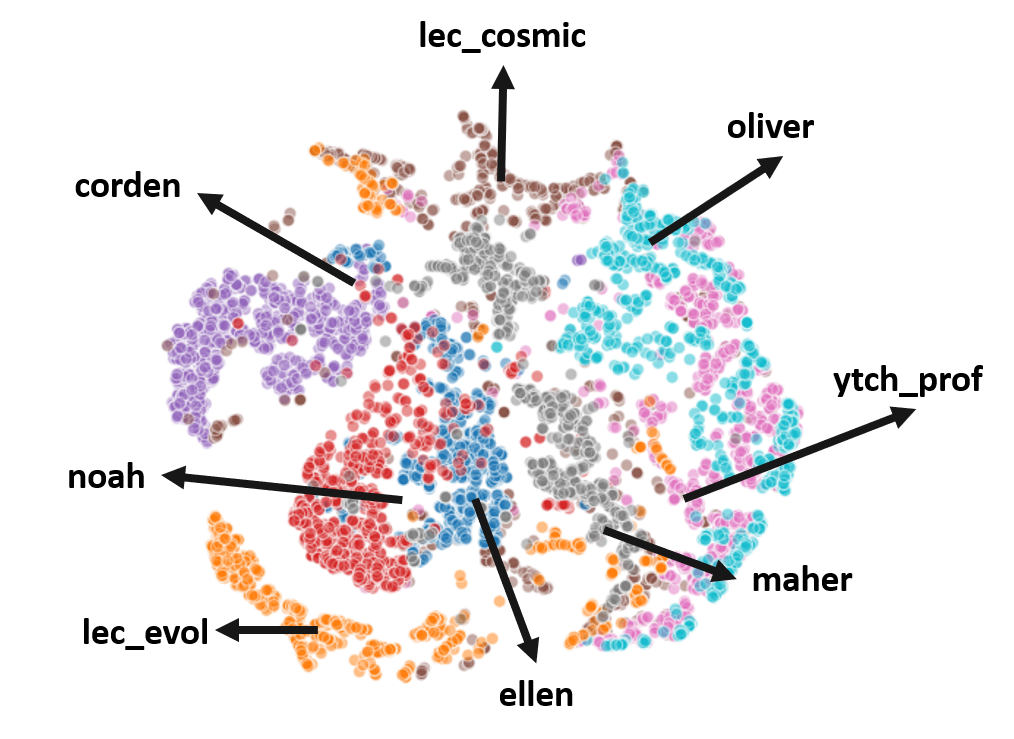
Style Preservation
Style:
Audio:
Style Transfer
Style:
Audio:
Style
Audio-0
Audio-1
Audio-2
Audio-3
Audio-4
Audio-5
Audio-6
Media Coverage
![]()
Acknowledgements
This material is based upon work partially supported by the National Science Foundation (Awards #1750439 #1722822), National Institutes of Health and the InMind project. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of National Science Foundation or National Institutes of Health, and no official endorsement should be inferred.